

환경
라즈베리파이 3B(crontab)
파이썬 3.5
제작에 앞서 크롤링하려는 웹페이지마다 로봇 배제 표준(robots.txt)을 명시하는 페이지들이 있다. 이는 웹 사이트에 로봇이 접근하는 것을 방지하기 위한 규약으로, 일반적 접근 제한에 대한 설명을 기술한다.
https://ko.wikipedia.org/wiki/%EB%A1%9C%EB%B4%87_%EB%B0%B0%EC%A0%9C_%ED%91%9C%EC%A4%80
허가된 영역, 자원만을 크롤링하는 것을 권장한다.
제작하려는 스크립트는 새 글이 등록되었을 때 텔레그램 메신저로 알림이 오도록 하는 것이다.
필요한 모듈을 설치해 준다.
sudo pip3 install requests # http request
sudo pip3 install bs4 # BeautifulSoup4 설치
sudo pip3 install lxml # lxml 설치
가져오려는 항목이 어느 태그에 포함되어 있는지 알아야 한다.
크롬 브라우저의 개발자모드(F12)를 이용한다.

Ctrl + Shift + C를 누르면 현재 마우스가 위치한 곳의 elements를 검사하여 html내의 태그 위치가 highlight 된다.
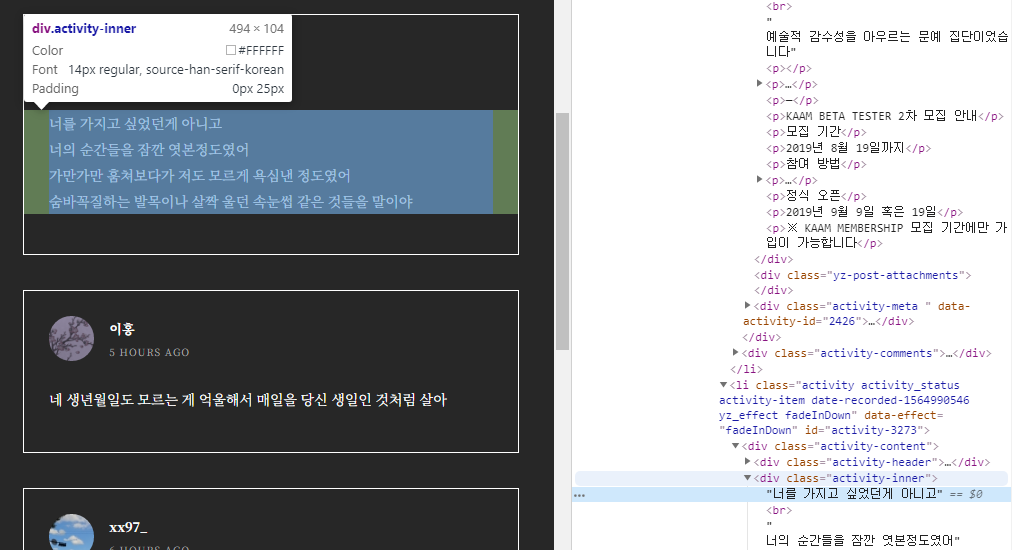
<div class="activity-content> >> <div class="activity-header"> >> <div class="activity-inner"> ~ </div>
아래에 원하는 항목이 위치하고 있다는 것을 알 수 있다.
정확한 위치를 알기 위해서는 태그에서 오른쪽마우스 클릭 - Copy - Copy selecter 를 선택하시면 클립보드에 복사가 된다.
#activity-3269 > div.activity-content > div.activity-inner원하는 정보가 있는 위치를 알았으면 bs4의 select의 사용으로 크롤링 할 수 있다.
먼저 soup 객체를 선언한다. 이는 '태그'들로 구성되어 있는 html 문서를 Python이 객체로 읽을 수 있도록 해준다.
import requests
from bs4 import BeautifulSoup
req = requests.get(url) # url = 크롤링하려는 사이트의 url
html = req.text
soup = BeautifulSoup(html, 'lxml') # lxml 빠르고 관대한 탐색
※ bs4로 원하는 요소들이 제대로 탐색되지 않는다면 파서의 종류를 변경해보는 방법도 권해본다.
| Parser | 선언 | 장점 | 단점 |
| 내장 html.parser | BeautifulSoup(html, 'html.parser') |
적당한 속도, 내장 parser |
|
| lxml HTML parser(외부 C 라이브러리) | BeautifulSoup(html, 'lxml') | 유연하고 빠른 처리, 관대한 탐색 | 외부 모듈 설치 |
| lxml XML parser(외부 C 라이브러리) | BeautifulSoup(html, 'lxml-xml') | 유연하고 빠른 처리, 관대한 탐색, xml parser | 외부 모듈 설치 |
| html5lib | BeautifulSoup(html, 'html.html5lib') | 웹브라우저의 방식으로 파싱 | 외부 모듈 설치, 느림 |
보통 사용하는 것은 html.parser를 사용하지만 html로 정확하게 마크업되어 있지 않은 경우 lxml을 이용해서 처리되는 경우가 있다.
클래스 명을 알고 있기 때문에 클래스 명으로 탐색한다. 지정한 위치에서 .text를 사용하면 태그 안의 content를 가져올수 있다.
# title 태그 바로 아래 자식 검색
soup.select('head > title')[0]
속성정보를 가져오려면 속성정보를 명시하여 가져올 수도 있다.
select('a')[0]['href'] # 0번째 링크 주소
다른 탐색 방법은 bs4의 공식 문서를 참조하도록 하자
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
한글 번역된 버전은 다음과 같다.
태그나 CSS 기반으로 크롤러를 제작했을 때 사이트의 DOM이 변경되면 당연히 크롤링이 제대로 되지 않는다. 그 경우에는 다시 태그를 지정하여 가져오도록 해야 한다.
다시 코드로 돌아가서
.은 태그의 클래스 명을 검색한다. 'class'는 파이썬에서 예약어이므로 'class_'를 사용한다.
posts = soup.find_all("div", class_='activity-inner')
newposts = [Member.get_text().strip() for Member in posts]
activity-inner 클래스 아래의 정보들을 posts 객체에 저장한 후 list comprehension을 통해 저장하였다.
newposts 리스트에는 str형으로 요소들이 저장된다.

이 리스트를 pickle module로 저장하여 일정 주기로 실행시켜서 새로운 글이 등록되었을 때 이전에 저장된 리스트와 새로운 리스트를 비교하여 새로 올라온 게시글만 확인하여 알림을 전송한다.
마지막 올라온 글만 변수에 저장하여 알고리즘을 구성해도 되지만 실행주기가 길고 여러개의 새 글이 등록될 수 있기 때문이다. 물론 더 빠르고 나은 방법이 있을 수 있다.
import pickle
import os.path
try:
with open(os.path.join(BASE_DIR, 'data.pickle'), 'rb') as f_read:
before = pickle.load(f_read)
if before != newposts: # 같지 않다 == 새로 등록된 글이 있다
new = list(set(newposts) - set(before)) # 리스트 간 차집합
for i in new:
print(i) # 새로 등록된 글 출력
with open(os.path.join(BASE_DIR, 'data.pickle'), 'wb') as f_write:
pickle.dump(newposts, f_write, pickle.HIGHEST_PROTOCOL)
else:
print("file is same")
except FileNotFoundError: # 최초 실행시 data.pickle 파일 생성
with open(os.path.join(BASE_DIR, 'data.pickle'), 'wb') as f_write:
pickle.dump(newposts, f_write, pickle.HIGHEST_PROTOCOL)
리스트 간 차집합으로 새글을 구분하게 되면 게시글이 순서대로 나오지 않는다. 이 프로그램은 글의 순서가 중요하지 않기 때문에 상관이 없지만 순서가 보존될 필요가 있는 경우 다음과 같이 쓸 수 있다.
s = set(before)
result = [x for x in after if x not in s]
이제 라즈베리파이 crontab 데몬에 등록해준다.
crontab -e


텔레그램 봇을 생성하고 메시지를 전송하는 방법은 2편에서 다룬다.
'Side Project > Telegram Chatbot' 카테고리의 다른 글
| 텔레그램 봇과 MySQL 연동하기 (0) | 2020.12.03 |
|---|---|
| [python]라즈베리파이 서버정보 파싱 (0) | 2020.12.02 |
| [Telegram Bot] lol api 이용한 게임 알림 챗봇 제작기 (0) | 2020.11.26 |
| [BeautifulSoup4] Python 게시판 크롤러 텔레그램 봇 제작기(2) (0) | 2020.02.22 |